En el entorno corporativo actual, la mayoría de las iniciativas de IA fracasan no por falta de capacidad del modelo, sino por una arquitectura deficiente. El enfoque tradicional de «el modelo primero» —obsesionarse con elegir entre GPT-4 o Claude antes de definir el sistema— es una receta para el desastre financiero.
- Gap de Observabilidad: Sin una trazabilidad completa de cada decisión, el sistema es una «caja negra» inaceptable para auditorías y cumplimiento. Si no podemos ver, no podemos corregir ni escalar.
- Gap de Evaluación: La ausencia de métricas de negocio precisas y sistemas de medición continua impide validar el retorno de inversión (ROI). La «precisión» vaga no es una métrica; el éxito debe ser cuantificable y constante.
- Gap de Gobernanza: La falta de rendición de cuentas operativa. Es crítico definir quién es el dueño de los activos de datos y quién responde ante un fallo sistémico a las 3:00 a.m. o ante un comportamiento no ético del agente.
Para mitigar estos riesgos, la implementación debe estructurarse sobre cinco pilares diseñados para transformar la IA en un activo gobernado, medible y, sobre todo, rentable.
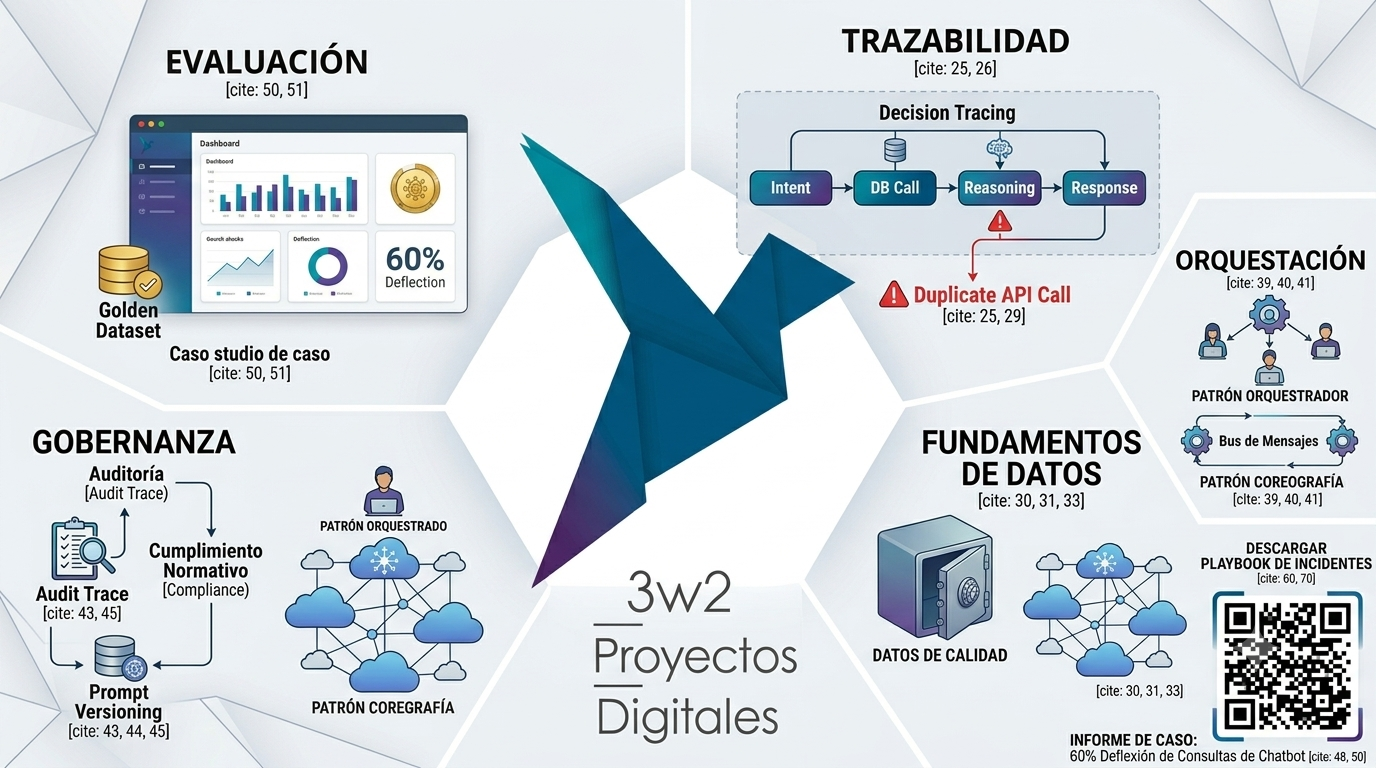
Pilar I: Marco de Evaluación Continua (Evaluation-First)
La arquitectura de evaluación debe implementarse en tres capas progresivas:
|
Capa de Evaluación
|
Descripción de Alcance
|
Ejemplos de Aplicación
|
|---|---|---|
|
Capa 1: Determinista
|
Verificaciones objetivas, rápidas y de bajo costo.
|
Validación de formatos (Regex), detección de PII mediante modelos de ML clásico (NER) y clasificación de intención.
|
|
Capa 2: Semántica (LLM-as-a-judge)
|
Evaluación del significado, veracidad y seguridad.
|
Uso de un LLM secundario para juzgar la coherencia, el tono y el groundedness (basado en evidencia) del modelo primario.
|
|
Capa 3: Conductual
|
Optimización de OpEx y eficiencia operativa.
|
Detección de bucles, llamadas fallidas a herramientas y, crucialmente, identificación de llamadas duplicadas a APIs que disparan costos en la nube.
|
- Ingeniería de Dominio: Colaborar con expertos para capturar respuestas humanas reales frente a consultas críticas.
- Mapeo de Casos de Borde: Documentar áreas grises y preguntas confusas detectadas en la operación real.
- Automatización del Pipeline: Comparar sistemáticamente las respuestas de la IA contra este dataset de referencia.
- Evolución Post-Lanzamiento: El dataset no termina en el despliegue; debe crecer con cada fallo o «thumbs down» detectado en producción para evitar regresiones.
Una evaluación robusta es el cimiento que permite observar y auditar el comportamiento del sistema en tiempo real.
Pilar II: Observabilidad y Trazabilidad de Decisiones
- Clasificación de Intención: ¿Se identificó correctamente el deseo de condonación? (Registrar confianza y tiempo).
- Conexión de Datos: ¿A qué cuentas y APIs específicas accedió el sistema?
- Recuperación (RAG): ¿Qué documentos de política de sobregiro se extrajeron del vector store?
- Razonamiento: ¿Cómo aplicó el agente la política a los datos financieros del usuario?
- Verificación de Guardrails: ¿Superó la respuesta los filtros de seguridad antes de ser emitida?
Esta visibilidad es vital para la Eficiencia de OpEx. En una demo, tres llamadas duplicadas a una base de datos son irrelevantes; a escala de millones de consultas, son un fallo operativo costoso. La observabilidad permite implementar estrategias de fallback y reintentos limitados, protegiendo tanto el presupuesto como la experiencia del usuario.
Pilar III: Cimentación de Datos y Estrategia de Seguimiento
- Datos de Consulta (Question Data): Información para alimentar las respuestas (bases de datos, documentos, APIs).
- Datos de Seguimiento (Tracking Data): La telemetría y los rastreos (traces) generados por los agentes.
Es imperativo utilizar una capa de gobernanza unificada como Unity Catalog sobre arquitecturas Delta Lake. Esto permite gestionar metadatos, etiquetar columnas con PII y asegurar que los agentes operen sobre tablas con propiedades de base de datos robustas (vistas, versiones, permisos). Solo una base organizada permite la orquestación segura de múltiples agentes.
Pilar IV: Patrones de Orquestación Multi-Agente
- Orquestador-Trabajador: Control centralizado ideal para flujos que requieren registros consolidados y una supervisión estricta de cada paso.
- Coreografía: Los agentes reaccionan de forma independiente a un bus de mensajes. Reduce la latencia al permitir el procesamiento paralelo, pero requiere una gobernanza de eventos impecable.
- Humano en el Bucle (HITL): Intervención manual obligatoria cuando la confianza del agente cae por debajo de un umbral crítico.
Ingeniería de Resiliencia: Para sistemas críticos, es obligatorio implementar Patrones de Saga (para transacciones distribuidas), Patrones de Compensación (para revertir acciones tras un fallo) y Circuit Breakers (disyuntores) que eviten colapsos en cadena cuando una API externa falla.
Pilar V: Gobernanza, Riesgo y Gestión del Cambio
- Auditoría y PII: La implementación de capas de reconocimiento de entidades (NER) es innegociable. En entornos bancarios reales, este rigor ha permitido detectar hasta 47 brechas de PII durante fases de prueba, evitando desastres de privacidad.
- Prompt como Código: Los prompts deben tratarse con el mismo rigor que el software. Se requiere control de versiones (Git) y procesos formales de gestión del cambio.
- Independencia del Modelo: No se puede confiar en benchmarks genéricos de proveedores. Las empresas deben probar cada actualización de modelo contra sus propios datasets internos para detectar degradaciones antes de actualizar el entorno de producción.
Hoja de Ruta de Implementación (8 Semanas)
- Semanas 1-2: Definición de Éxito. Definición de targets (ej. 85% de precisión, 60% de tasa de deflexión). Construcción del «Dataset Dorado» inicial con al menos 200 casos de prueba curados.
- Semanas 3-6: Infraestructura y Trazabilidad. Configuración de la base de datos (Delta Lake), conexiones API y despliegue del sistema de observabilidad para detectar ineficiencias (como llamadas redundantes).
- Semanas 7-8: Selección Basada en Evidencia y Lanzamiento. Solo en este punto se comparan modelos contra el dataset de evaluación. Se selecciona el modelo con mejor rendimiento contextual, se integra la orquestación y se despliega.
Playbook de Respuesta a Incidentes en Producción
- Detectar: Monitoreo de dashboards de evaluación y caídas en el sentimiento del usuario (CSAT).
- Diagnosticar: Análisis de traces para identificar si el fallo está en la recuperación (RAG), el prompt o una API.
- Contener: Reversión a versiones anteriores de prompts, activación de fallbacks o desvío a humanos.
- Corregir: Actualización del dataset de pruebas con el nuevo caso de fallo para asegurar que el sistema no lo repita.
- Rigor en Commits de Prompts: Todo mensaje de commit en el repositorio de prompts debe vincularse a un fallo de producción específico o a un trace ID, documentando exactamente qué comportamiento se está corrigiendo.
- Gobernanza del Dataset: El Golden Dataset es una biblioteca viva que requiere un dueño (Data Steward) y categorización (seguridad, lógica, tono).
- Control de Costos de Evaluación: Las evaluaciones de Capa 3 son costosas. Regla de oro: Ejecutar el suite completo de pruebas solo al hacer merge a la rama
main; utilizar subconjuntos representativos para pruebas de CI/CD diarias.
